
SPARK Queries taking
minutes or hours to run?
Hitting out-of-memory errors before execution even starts? Abnormally high compile time?
TabbyDB by KwikQuery is a high-performance fork of Apache Spark that eliminates query planning bottlenecks and dramatically accelerates complex SQL workloads.
The Real Bottleneck in Apache Spark!
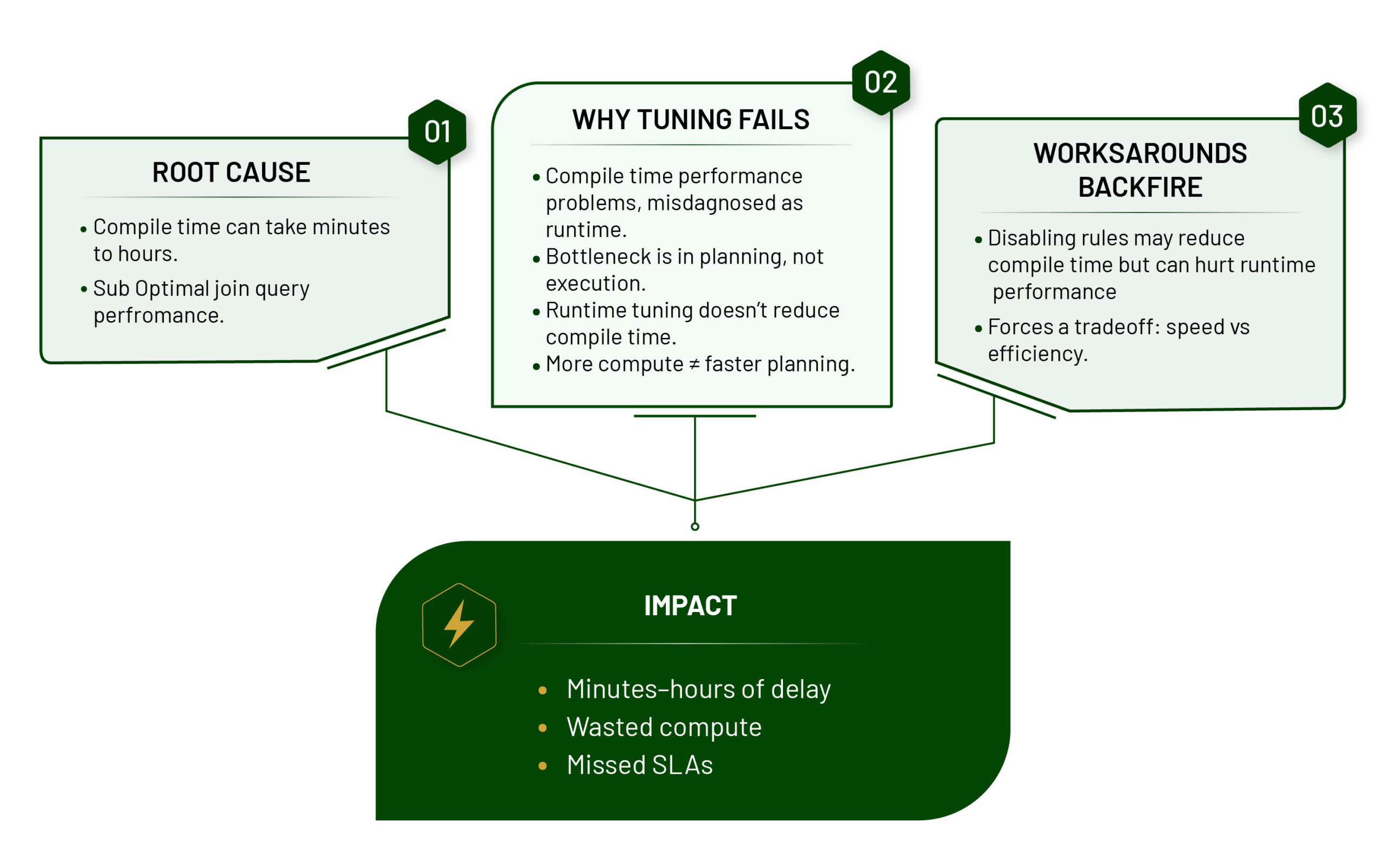
The Solution: KwikQuery's TabbyDB





Evaluate TabbyDB on Real Workloads
Explore how TabbyDB behaves on real, complex queries using interactive Zeppelin notebooks.
Each notebook runs the same SQL and data on both stock Apache Spark and KwikQuery’s TabbyDB, allowing you to directly observe compile time performance boost.
Comparison Technique
- Identical queries executed in both environments
- Comparison Technique
- Resentative workloads that reflect complex, real-world usage
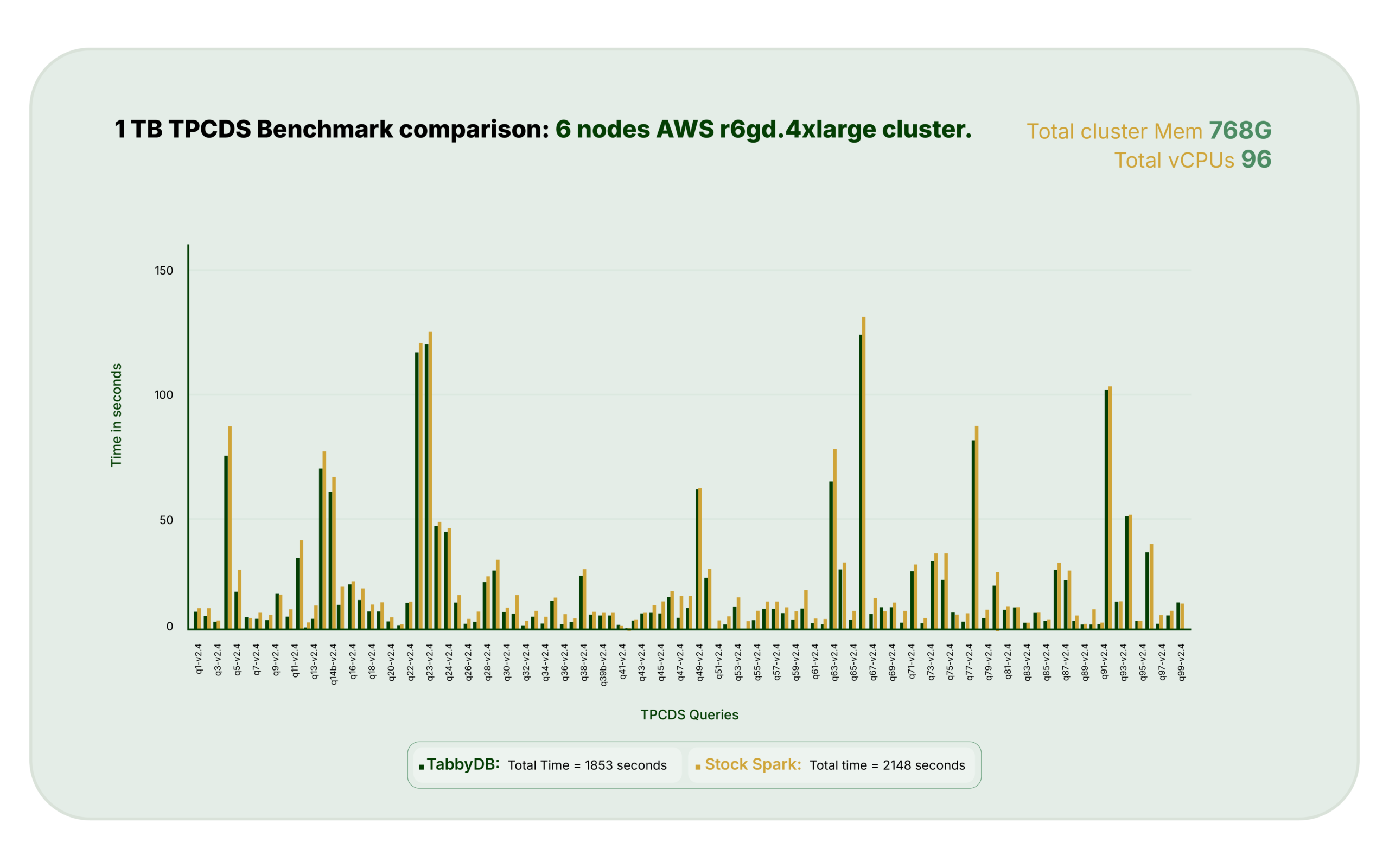
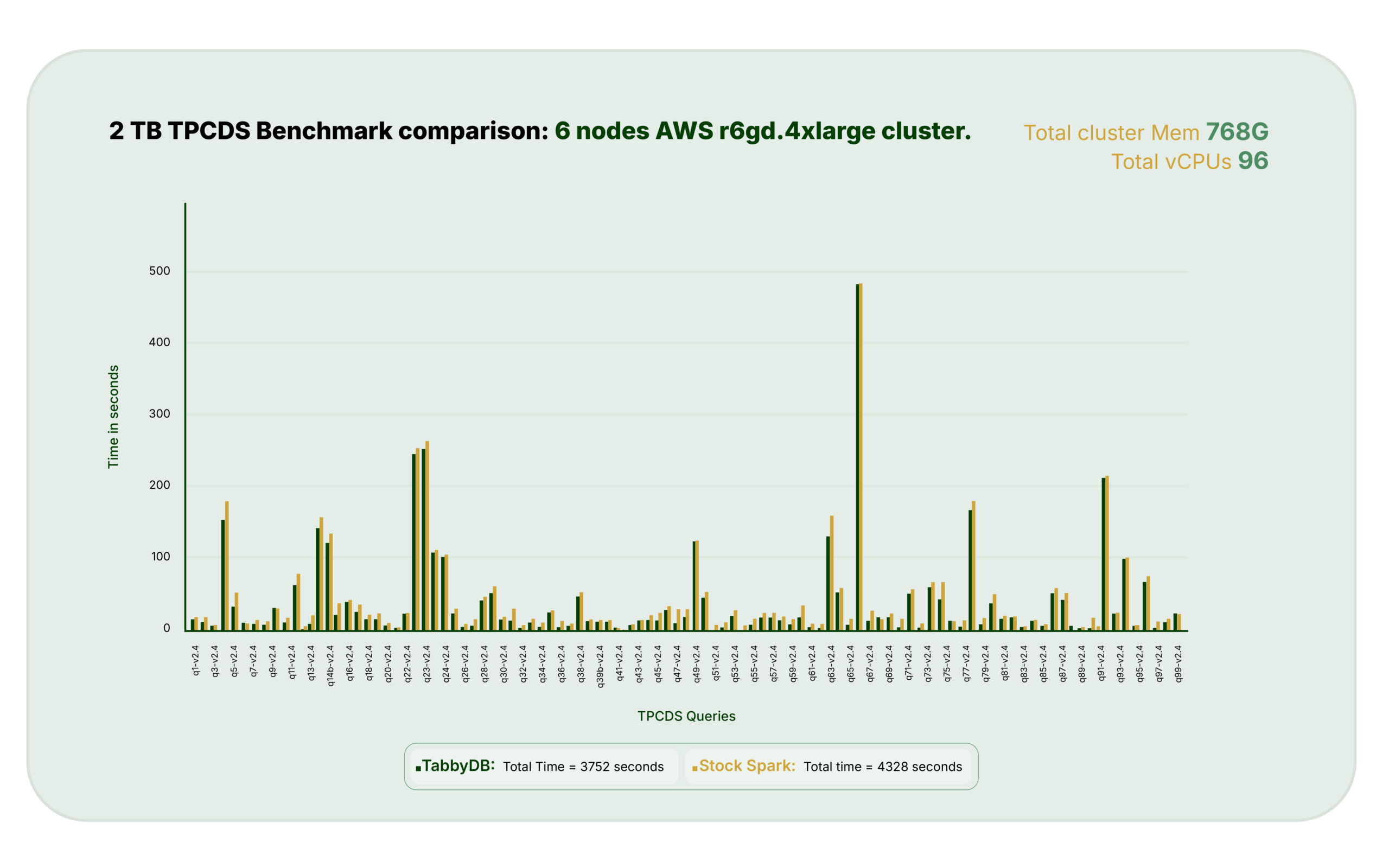
TPC-DS Benchmark Results: Execution-Time Focus
TPC-DS Context TPC-DS is a widely used analytical benchmark, but it does not fully represent the complexity of many production Spark workloads. Query structure is constrained, nesting depth is limited, and compilation overhead is typically not a dominant factor. In limited TPC-DS testing on 1 TB and 2 TB datasets, using Spark with Hive external, non-partitioned tables, TabbyDB demonstrated.
- 13% reduction in query execution time compared to stock Spark
- Improvements observed consistently across queries, rather than driven by isolated outliers
- These results primarily reflect runtime execution behavior, as TPC-DS queries do not meaningfully stress query compilation.
TPCDS Run Benchmark Comparison
Complex Production Workloads Differ from Benchmarks




Performance Issues
The following issues are associated with excessive compilation time, inefficient optimization behavior, or suboptimal runtime execution, especially in large or complex query plans:
- Spark-33152: Constraint Propogation rule causing query compilation tomes to run into hours.
- Spark-45866: Reuse of Exchange broken in AQE when runtime filters are pushed down to scan.
- Spark-47609: Cached Plan lookup may miss picking valid plan..
- Spark-49881: Minimizing the cost of DeduplicateRelations in the analyzer.
- Spark-36786: Inefficiency in Push Down Predicates rule affecting complex expressions.
- Spark-45959: Uncapped tree size in analysis phase, causing compilation to run into hours.
- Spark-49618: Canonicalization differences in Union may cause failure in reuse of exchange.
- Spark-55072: Inferring new Constraint misses Is Not Null on Left Leg.
- Spark-33152: Dynamic file pruning for non partition column joins.
- Spark-46671: Redundant filter creation due to buggy Constraint Propagation rule.
- Spark-54881: Boolean Simplification rule using transform Expressions Up.
- Spark-55110: Order of rules BooleanSimplification and Simplify Binary comparision.
Functional Issues
The following issues relate to query correctness, stability, and deterministic behavior in advanced Spark usage patterns, click to learn more:
- Spark-47320: Self join inconsistencies and exceptions.
- Spark-49727: Data Loss issue when POJO Dataset is converted into DataFrame and back.
- Spark-49789: Exception in encoding POJOs with generic type fields.
- Spark-51016: Incorrect results during retry when joining column is indeterministic.
- Spark-45658: Canonicalization of Dynamic Pruning Subquery is broken.
- Spark-53264: Incorrect nullability when correlated subquery gets converted to Left Outer Join.
- Spark-47217: DeduplicateRelations may cause failure in plan resolution.
- Spark-55185: Adding rule InferFiltersFromConstraints to the Batch “Operator Optimization after In.ferring Filters” causes idempotency break.
- Spark-55214: Idempotency of SQL Streaming involving Joins is broken if InferFiltersFromConstraint and PropagateEmptyRelation rules are added as part of Optimization rules.
Why Choose TabbyDB?
TabbyDB is built for teams running complex, production-critical Apache Spark workloads, where query compilation time, optimizer behavior, and correctness matter as much as execution speed.
Beyond performance improvements, TabbyDB reflects a deep focus on stability, predictability, and real-world Spark usage, informed by addressing long-standing issues in Spark’s SQL and optimizer layers.
Download TabbyDB
Upgrade your APACHE Spark instantly with TabbyDB!
Upgrade APACHE Spark with TabbyDB
Download the trial version of Tabby DB now! and for the next 3 months enjoy an instant upgrade to your Apache Spark. Contact us for the full version today!
Contact TabbyDB's Expert Team
Contact the TabbyDB team today! Our expert team will guide you on how to get the BEST perfomrance from your Apache Spark!
